

이번 주는 Tableau LOD를 포함하여 여러 중요하고 심화된 내용을 배운 주였다.
그리고 그것들을 이용하여 팀프로젝트를 진행했다.
오늘 포스팅에는 이번 주에 배운 내용을 총정리하는 시간을 가져보려고 한다.
프레젠테이션은 Top-Down 형식으로!
: 처음에 탑 다운 형식이라고 하셔서 당연히 의사결정 방식인줄 알았는데, 프레젠테이션 만들 때의 방식을 말씀하신거였다..
아마 두괄식 이런 느낌인가보다! 우리 조는 목적, 전략 등을 같은 폰트 크기로 나열했었는데 몇몇 다른 조 ppt를 보니까 우선 과제에 대한 대답을 축약하여 한 마디로 적었다.
한번 피드백을 받고나서 우리 조도 오른 쪽처럼 고쳐보았다. 확실히 눈에 더 잘 띄는 느낌이다.
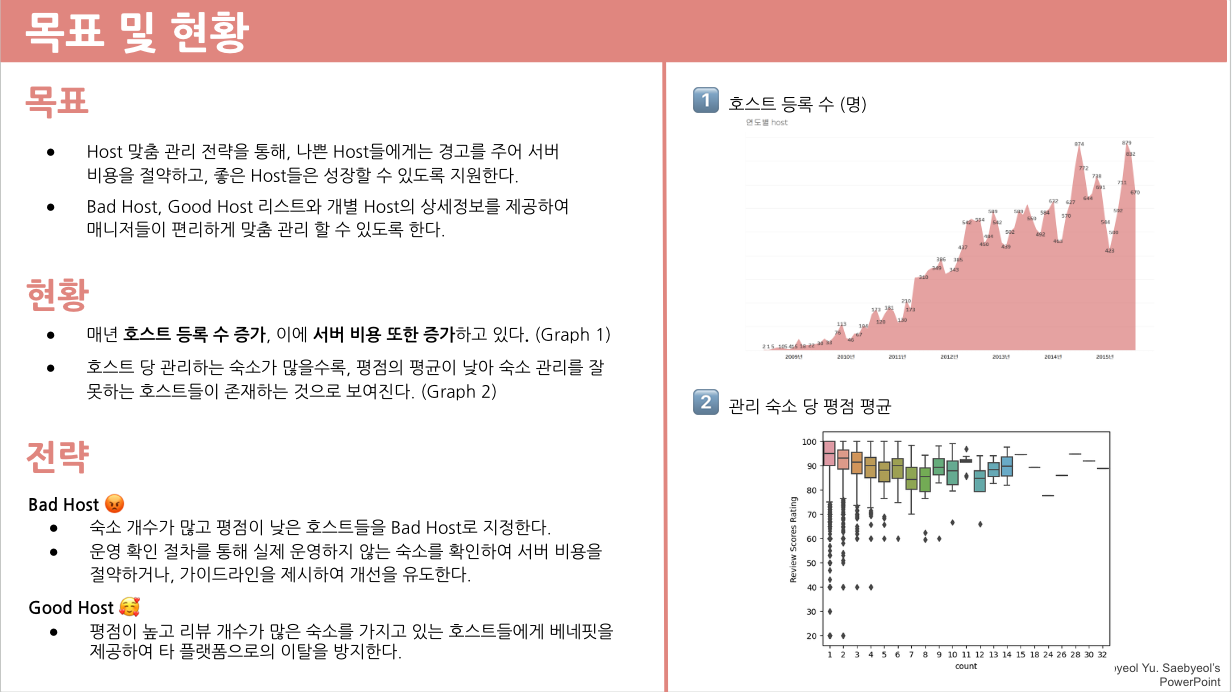

그리고 우리 조는 저 설명할 수 없는 우측 하단의 박스플롯에 피드백을 많이 받았다. ㅠ
방이 많아질수록 평점이 안좋아진다는걸 설명하는 내용이었는데, 일단 박스플롯 형식을 다른 분들이 잘 이해하지 못할 수 있다는 피드백과 저 자료를 보여주고 그래서 정말 방이 많아질수록 평균이 낮아진건지? 신뢰성이 있는지 등의 문제였다.
사실 이미 에어비앤비 대시보드를 만들고 나서 저런걸 끼워넣으려니, 뭔가 억지스러운 느낌이 있었던 것 같다.
그래서 태클이 들어올 수도 있는 부분은 안 쓰는게 나았을 것 같다.!
Primary 함수
다음으로는 프라이머리 함수에 대해 배웠다. 프라이머리 함수에는 아래 함수 등이 있는데, 우선 프라이머리 함수는
VLOD에 없으면 보지 못한다는 것이고, 원하는 결과값만 볼 수도 없다는 것이다.
- Window()
- WINDOW_AVG(sum(sales), -1, 1) : 전달부터 다음달까지 매출의 평균
- 값이 3개가 아닐 때 null 나오게 하기 : 만약 첫행이라 -1자리 값이 없으면 0,1 자리의 두개 평균만 반환하는데 그것을 방지 하기 위해 아래와 같이 식을 써줄 수 있다.
- window_avg 할 때, 연도가 넘어가거나 분기가 넘어가게 되면 어떻게 계산할까? 저번연도 저번달의 마지막 값을 잘 끌어와서 3개로 계산함.
- WINDOW_AVG(sum(sales), -1, 1) : 전달부터 다음달까지 매출의 평균
IF WINDOW_COUNT(sum(sales), -1, 1) = 3
THEN WINDOW_AVG(sum(sales), -1, 1)
ELSE NULL END
- Total()
- TOTAL(sum(sales)) : 전체 매출, 차원이 나뉘는걸 신경쓰지 않는다. 비중을 구할 때 쓰임
- 구성비율 구하기 : sum(sales) / total(sum(sales))
- Previous_value()
- PREVIOUS_VALUE(0) : 이전값 반환
- Lookup(식, n)
- n자리의 값을 반환한다.
- Running()
- RUNNING_SUM(sum(sales)) : 누계
MoM 식
# 1.이후 서식 누르고 퍼센테이지로 변환 + 소수점 자리 변경
(sum(if datediff(‘month’,[Order Date],today())=1 then [Profit] END)
/sum(if datediff(‘month’,[Order Date],today())=2 then [Profit] END)) -1
# 2. LOOKUP 사용해서 만들기
sum([Sales]) / LOOKUP(sum([Sales]), -1) -1
MoM 을 매개변수에 따라 다르게 보여주기 (M-1, M-2)
1. 매개변수 만들기
매개변수는 문자열로 값은 1,2로 셋팅 (표시형식만 제대로 보여주기)
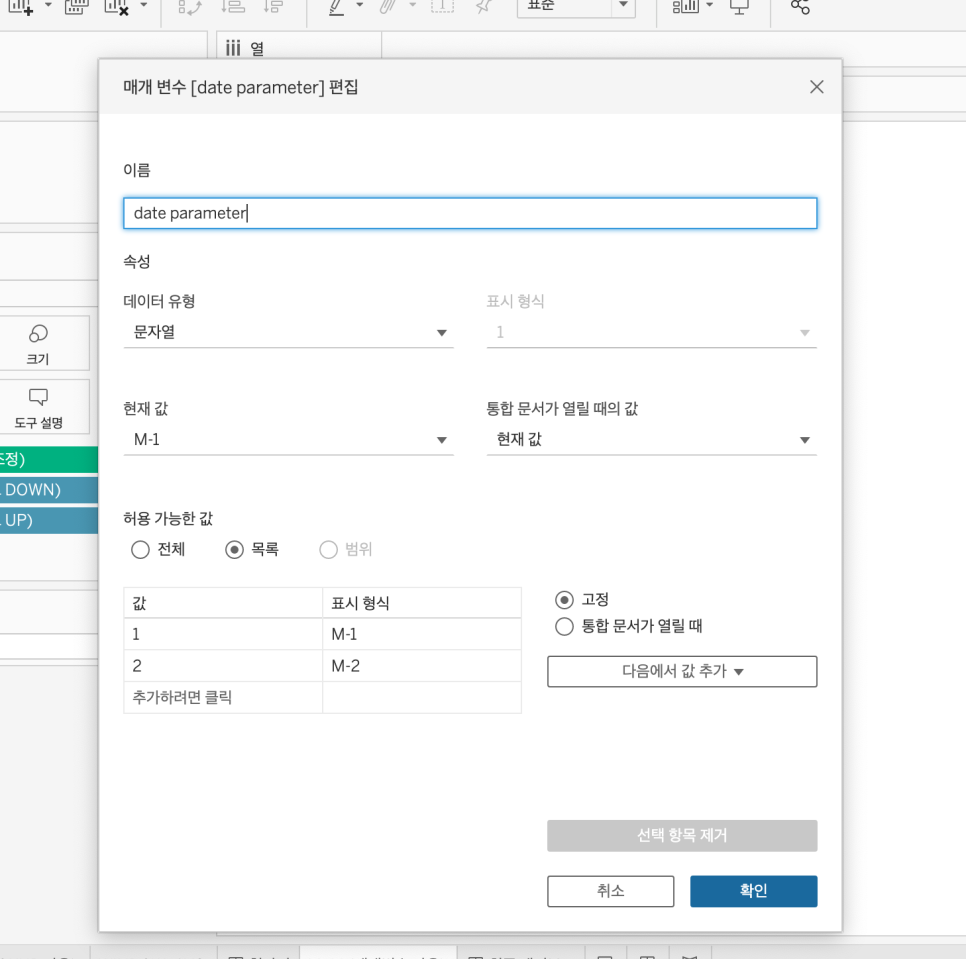
2. 계산된 필드 만들기
CASE [date parameter]
when '1' then
SUM(IF
DATEDIFF('month', [Order Date], date('2022-12-01')) = 1
THEN [Sales] END)
/
SUM(IF
DATEDIFF('month', [Order Date], date('2022-12-01')) = 2
THEN [Sales] END)
-1
when '2' then
SUM(IF
DATEDIFF('month', [Order Date], date('2022-12-01')) = 2
THEN [Sales] END)
/
SUM(IF
DATEDIFF('month', [Order Date], date('2022-12-01')) = 3
THEN [Sales] END)
-1
END
MTD, YTD
MTD란 이번달 첫날부터~오늘까지의 지표 합
아래처럼 date parameter로 날짜 매개변수로 조정하면, 이번달 첫날부터~선택한 날짜까지
DATEDIFF('month',[Order Date], [date_parameter]) = 0
and DATEDIFF('day',[Order Date], [date_parameter]) >= 0
ATTR 함수
집계 함수다.
현재 VLOD에서 이 필드가 단 하나의 값을 가지면 그것을 가져오고 아니면 *을 가져와라.
1. 차원을 측정값으로 바꿀 때
2. 같은 차원 다른 집계
example 1) 한 번만 팔린 제품 찾기
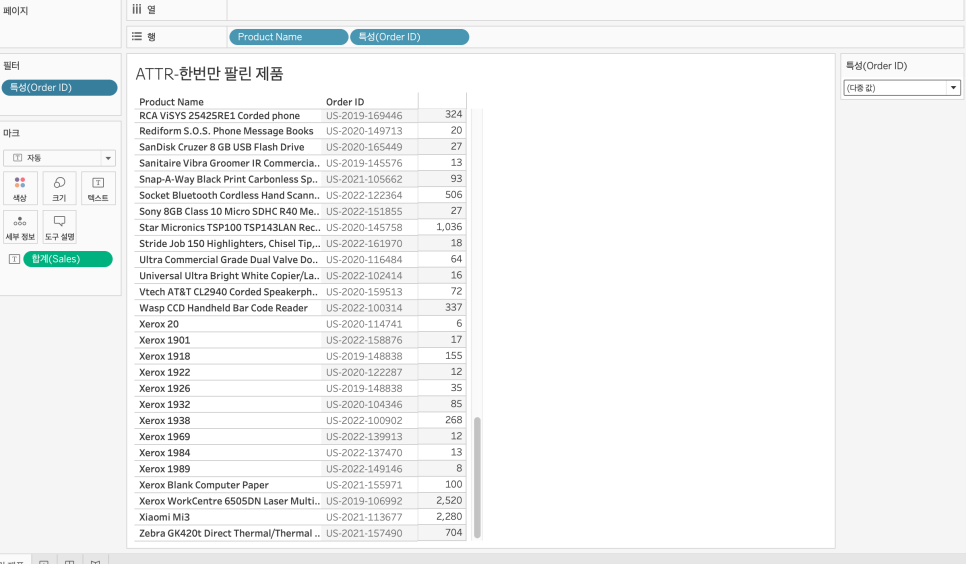
example 2) 하나의 차원에 다른 집계 넣기
central일 때는 SUM하고 다른 Reigion일 때는 평균 구하기
IF ATTR([Region]) = 'Central' THEN SUM([Sales])
ELSE AVG([Sales])
END
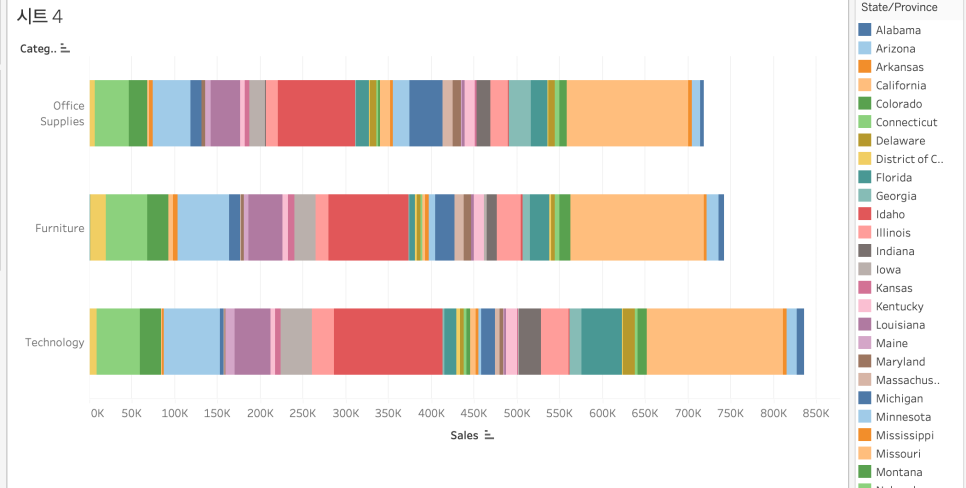
Nested Setting
각 카테고리 안에서 sales 순으로 정렬하고 싶은데, 정렬이 안될 때
1. 결합된 필드 만들기

2. 그 결합된 필드를 세부 정보로 가져오기 (제일 상단으로), 그리고 정렬을 '필드'로 변경하고 sum(sales)기준으로 정렬
정렬이 되지 않던 좌측에서 우측 정렬로 깔끔하게 변경됨.

집합
둘이 분리 하는 것, 제외는 아님
필터와 다른점 ? 필터는 관심있는 값만 가져오는 것이다.
집합은 필터보다 상위의 개념이라 집합을 필터로 넣으면 사용 가능
T/F 필터 vs 집합
집합 : IN/OUT 기준은 집계된 값인 customer name의 SUM(Sales) 기준
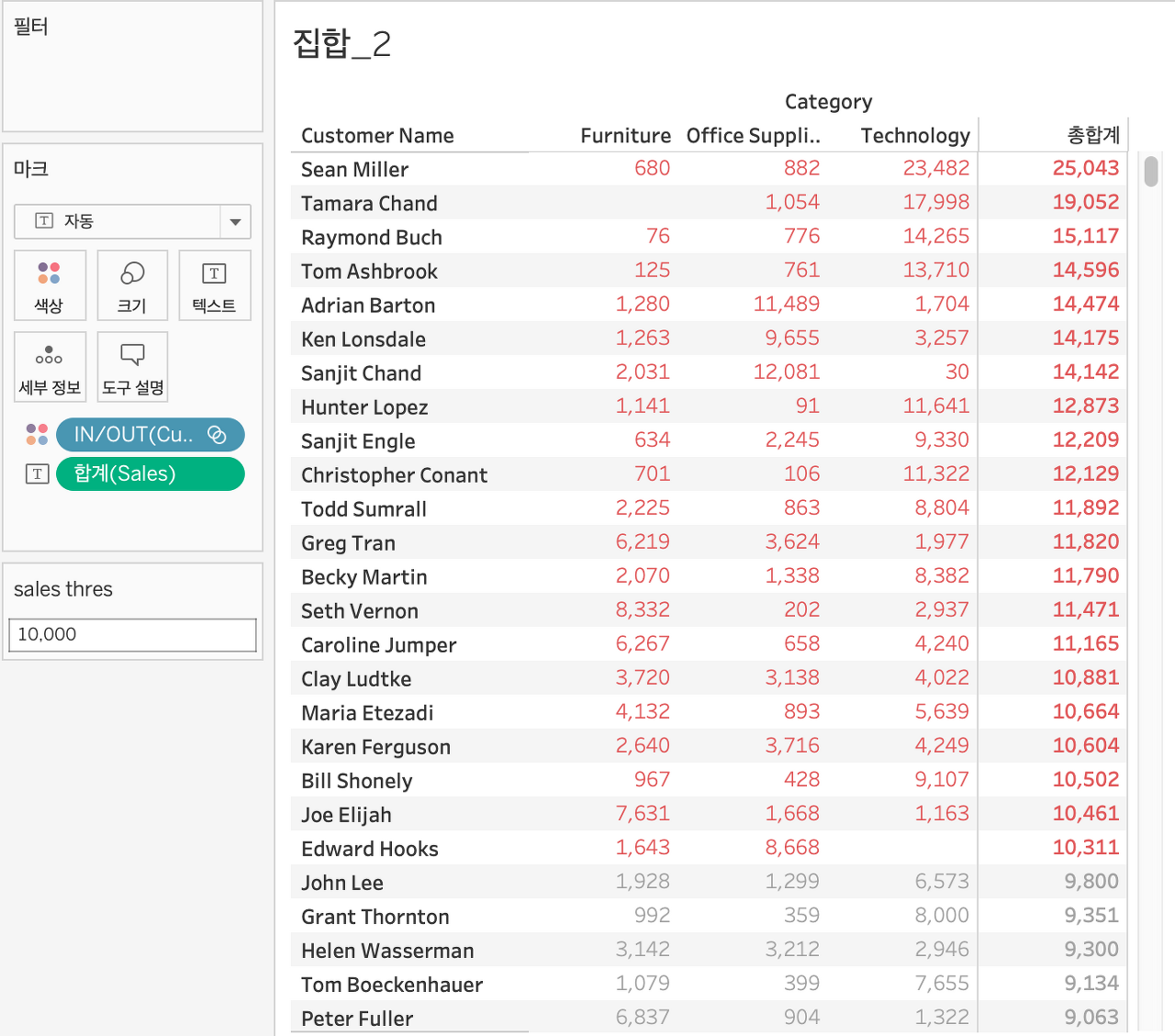
T/F 필터 : VLOD에서의 SUM(Sales) 기준
기준이 customer name이 아니라 VLOD에서 threshold를 넘는 것을 표시

LOD : INCLUDE (VLOD에서 설정한 차원의 영향을 받음)
1. 데이터의 depth가 상대적으로 깊거나,집계를 두 번 해야할 때
2. 필터에 영향을 받는다.
3. 결과는 항상 측정값으로 나온다.
example 1) include를 사용하면 좀 더 인사이트를 얻을 수 있다.
좌측을 보면, 이 도시가 그냥 매출이 낮은게 아니라 격차가 크다는 것을 알 수 있음.
{ INCLUDE [도시] : AVG([매출])}

LOD : EXCLUDE (VLOD에서 설정한 차원의 영향을 받음)
1. EXCLUDE LOD에 명시된 차원이 하위 범주에 그대로 복제 됨.
2. 선언된 차원이 반드시 VLOD에 들어가 있어야 활용도가 높다.
3. 필터에 영향을 받음.
4. 결과는 항상 측정값으로 나온다.
example 1) 기여도
SUM([Profit])/ ATTR({ EXCLUDE [City] : SUM([Profit])})
example 2) 선택된 하위범주와의 차이
SUM([매출])
-
ATTR({ EXCLUDE [하위 범주] : sum(IF [하위 범주] = [Sub category_parameter]
THEN [매출]
ELSE NULL END) })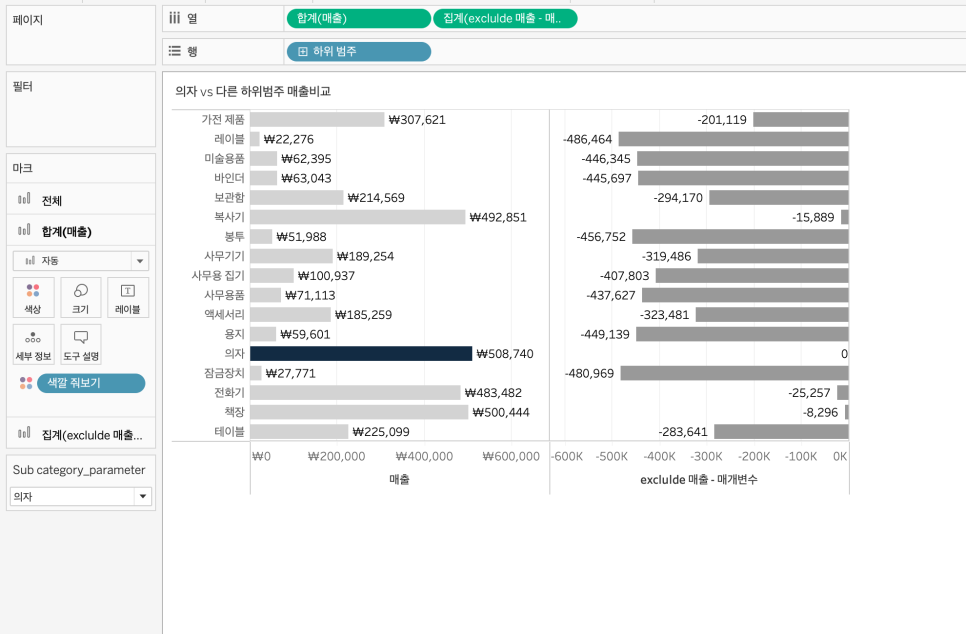
LOD : FIXED (VLOD에서 설정한 차원의 영향을 받지 않음)
1. 유연함
2. 필터에 영향을 받지 않는다.
3. 작동 순서에서 상위에 위치하고 제어하는 개념으로는 컨텍스트 필터가 있음.
4. 결과가 측정값 또는 차원으로 나옴.
5. 중복 확인용으로도 쓰임.
VLOD에 고정시킨 차원이 나타나 있지 않을 경우
example 1) profit > 0인 주문 id가 차지하는 매출의 비율
1. sum(sales)를 열로 가져다 놓고, 구성비율, 테이블 계산 옆으로로 변경
2. 계산된 필드 만들고 색상으로 가져다 놓기.
{ FIXED [주문 Id] : SUM([수익]) > 0 }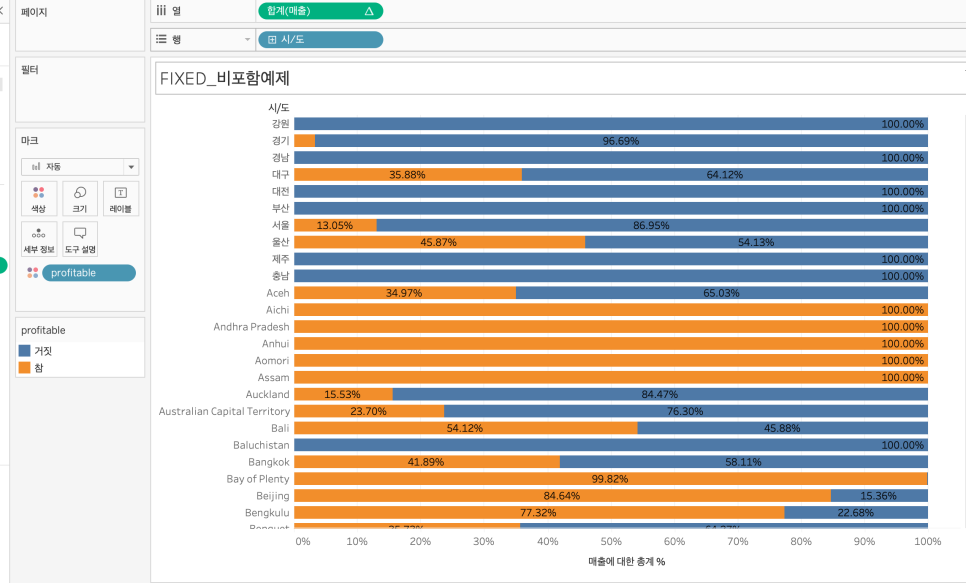
VLOD에 고정시킨 차원이 나타나 있는 경우
{ FIXED [하위 범주] : AVG([매출]) }
팀프로젝트를 통해 배운 것
팀프로젝트는 태블로에 내장되어 있는 superstore 데이터셋을 이용하여 상품 세일즈 트래킹 대시보드를 만드는 것이었다.
조건으로는 LOD를 사용해야 한다가 있었다.
우리 조의 결과물은 아래와 같았고, 과정을 진행하면서 두 가지 새로운 점을 발견했다.


1. 오른쪽 대시보드 좌측 하단의 profit>0인 매출 비중을 구하고 나서 저 참/거짓 값으로 정렬이 하고 싶었는데 정렬이 안되었다.
똑같은 값을 나타내는 계산된 필드를 만들고 그 필드를 기준으로 정렬하려고 했으나, 그 필드가 정렬 기준에 뜨지 않았다.
SUM(IF {FIXED [Order ID]:SUM([Profit])>0} THEN [Sales] END) /
ATTR({FIXED [c.sub/state]:SUM([Sales])})-> 이유 : ATTR은 정렬 기준으로 쓸 수 없다.
SUM(IF {FIXED [Order ID]:SUM([Profit])>0} THEN [Sales] END) /
AVG({FIXED [c.sub/state]:SUM([Sales])})
위처럼 AVG로 바꾸니까 바로 정렬 기준에 떠서 정렬할 수 있었다! (어차피 값은 같음)
2. 매개변수로 카테고리 선택하게 할 시, 총 값은 어떻게 나타낼까?
필터는 항상 전체 값 보기가 있어서 편리하게 사용해왔지만 매개변수로 사용시, 총 값을 나타내려면 계산식을 수정해야 한다.
우선 매개변수에 All 값을 추가해 준뒤 , 아래처럼 계산식을 수정해주었다.
IF [sub-category 선택] = 'All' THEN SUM([Sales]) / TOTAL(SUM([Sales]))
ELSE SUM(IF [Sub-Category] = [sub-category 선택] THEN [Sales] END)
/ TOTAL(SUM(IF [Sub-Category] = [sub-category 선택] THEN [Sales] END)) END
팀프로젝트에서 내가 맡은 역할 정리
우선 우리 조는 다른 조에 비해 한 명이 부족한 총 세명이고, 다들 의견도 잘 내고 또 이게 맞다 싶으면 따라가는 것도 잘하는 성향이셨던 것 같다.
물론 나도 마찬가지고 이번 팀프로젝트에서는 리더와 팔로워의 역할이 반반 정도 섞여있었다고 생각한다.
예를 들면, 우선 처음에 이런 차트를 넣는게 좋지 않을까? 아래에는 어떤 차트를 넣을까 이 부분은 카테고리를 보여주었으니 이 부분은 지역을 보여주는 게 낫지 않을까 하는 브레인 스토밍을 통해서 여러 의견이 나오면 토론 형식으로 이거는 ~ 때문에 기각. 이거는 ~ 가 좋아서 채택 이런식으로 진행된 내용을 정리해서 만들어졌다.
물론 명확한 리더와 팔로워가 있는 조도 있었을 거고, 다음 프로젝트때는 어느 한 역할을 중점적으로 하게 될 수도 있을거 같다.
대학교 시절에도 리더일때는 리더를 해왔고 팔로워일때는 곧잘 따라가기도 해서 어떤 부분이 더 잘맞는다고 아직은 말하기가 어려운 것 같다! 어쨋든 이번 조에서는 반반 역할로 진행되어서 다음주부터 만나게 될 새로운 조에서는 어떤 식으로 흘러가게 될지 ! 기대중이다 ㅎㅎㅎ..
* 유데미 큐레이션 바로가기 : https://bit.ly/3HRWeVL
* STARTERS 취업 부트캠프 공식 블로그 : https://blog.naver.com/udemy-wjtb
본 후기는 유데미-웅진씽크빅 취업 부트캠프 4기 데이터분석/시각화 학습 일지 리뷰로 작성되었습니다.
'유데미 스타터스' 카테고리의 다른 글
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 9주차 학습일지 (0) | 2023.04.09 |
|---|---|
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 8주차 학습일지 (0) | 2023.04.02 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 6주차 학습일지 (0) | 2023.03.19 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 5주차 학습일지 (0) | 2023.03.12 |
| 유데미 스타터스 취업 부트캠프 4기 - 데이터분석/시각화(태블로) 4주차 학습 일지 (1) | 2023.03.05 |